前言
在之前的几篇文章中,我们简单介绍了 SVM 的来龙去脉,从想要最大化分类间隔出发,然后将问题整理为一个QP问题,并在这个过程中引入了 Kernel Trick,最后将整理后的原始问题的求解转化为其对应的对偶问题的求解,对偶问题仍然是一个QP问题,可以使用一些现成的工具包来求解,到这里就可以说自己已经掌握了 SVM 这个算法的核心思想了,但是不知道大家是否和我一样心里会有一点别扭的地方:由于 QP 问题的求解需要依赖工具包,貌似我不能完全从头实现一个 SVM ,除非我自己去实现一个求解 QP 问题的工具包:),而这似乎不太现实。 我记得以前看过一句话,“what I can’t create it, I don’t understand it.”, 所以,我们还是要坚持自己去实现它,那应该怎么办呢?很简单,QP Solver 很难实现,那咱们就换一种求解方法呗,这就是本文提到的 Sequential Minimal Optimization Algorithm(序列最小优化算法),在下文中将其简单记为SMO,顺便说一句,在真正的 SVM 工业级实现像LIBSVM 中,往往也是采用的SMO 算法。
坐标上升法
在看 SMO 之前,我们先简单地看一下另外一个有趣的算法:coordinate asent。 考虑这样的一个优化问题: $$\max_\alpha W(\alpha_1,\alpha_2,\dots,\alpha_m)$$ 其中,$W$ 是 $\alpha_i$ 的函数,我们要求一个无约束的最大化问题,这里的问题仅仅是为了举例,跟 SVM算法没有任何关系。 类似于我们之前看过的一些最优化方法,像梯度下降法、牛顿法、fisher scoreing等等,这里我们采用的最优化方法就叫做coordinate asent,流程如下:
Loop until convergence: { For i = 1,…,m, { $\alpha_i:=\arg\max_{\hat\alpha_i}W(\alpha_1,\alpha_2,\dots,\alpha_{i-1},\hat\alpha_i,\alpha_{i+1},\dots\alpha_m)$ } }
简单来说,我们在内层的 for 循环中,固定除了 $\alpha_i$ 之外的所有参数,调整 $\alpha_i$ 使目标函数最大,在这个例子中,我们使顺序地修改 $\alpha_i$,与梯度下降法类似,我们也可以选定一些不同地方法使得算法更快地收敛,这里不再赘述。
coordinate asent 通常来说是一个很有效地算法,算法的实际运行效果通常如下图所示:
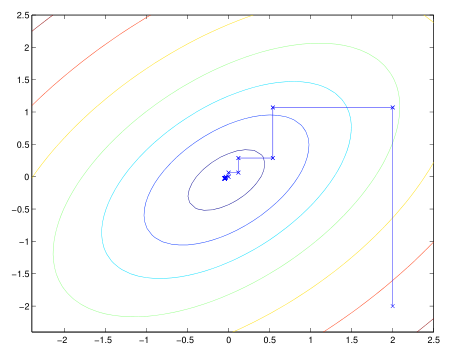 其中,椭圆线是我们目标函数的等值线,变量初始化为(2,-2),蓝色的线段是在 coordinate asent 的过程中,变量的取值,可以看到这些线段平行于坐标轴,这对应着我们在
其中,椭圆线是我们目标函数的等值线,变量初始化为(2,-2),蓝色的线段是在 coordinate asent 的过程中,变量的取值,可以看到这些线段平行于坐标轴,这对应着我们在 for 循环中每次只优化其中的一个变量。
BUFF - Sequential Minimal Optimization
终于到了我们的buff time, 在熟悉 coordinate asent 之后,我们来看看SMO具体是怎么工作的, 首先,我们先来回顾一下我们需要解决的问题,即SVM的对偶形式: $$\begin{split} \max_\alpha &W(\alpha) = \sum_{i=1}^m\alpha_i - \frac 12\sum_{i,j=1}^m y_iy_j\alpha_i\alpha_jK(x_i,x_j)\newline &s.t. 0 \leq \alpha_i \leq C, i=1,\dots,m \newline &\sum_i^m\alpha_iy_i = 0 \end{split}$$
为了求解最终的 $\alpha$, 我们需要搜寻对偶问题的可行域,寻找一个目标函数最大的可行解,似乎我们可以用 coordinate asent 来解决这个问题,我们来看看行不行。 假设我们现在手里有一组 $\alpha_i$ 满足问题的约束条件,现在我们想对其中一个 $\alpha_i$,不失一般性,我们取 $\alpha_1$,做最佳化动作,同时固定其他的 $\alpha_i$ 不动,目标函数的值会增加吗?显然不会,因为 $\alpha_1$ 根本就不会变化,因为,根据问题的第二个约束条件以及$y_1^2 = 1$,有 $$\alpha_1 = - y_1\sum_{i=2}^m\alpha_iy_i$$ 可以看到,$\alpha_1$ 被其他的 $\alpha_i$ 所决定,如果固定其他的 $\alpha_i$ 不变,在约束条件的限制下,我们根本无法取得更优的结果。
因此,为了在保证满足约束条件的前提下优化目标函数的值,我们至少需要同时更新两个 $\alpha_i$ 的值,这就是 SMO 算法,不严谨的说,可以看作在一次循环中同时更新两个自变量的 coordinate asent,SMO算法其实是将这个大的优化问题分解成了一系列小的优化问题,然后再分别求解,算法的流程大致如下:
重复以下过程直至收敛{
- 选择一对 $\alpha_i$ 和 $\alpha_j$ 进行更新(至于具体的选择哪些 $\alpha_i$, 会有一些启发式的方法针对性地选择使得算法会更快地收敛,下文会具体地介绍。) 2.固定其他的$\alpha$ , 针对 $\alpha_i$ 和 $\alpha_j$ 进行最优化动作。 }
OK, 思路很清晰,算法流程看起来也很简单:),但是细想你就会发现几个小问题:
- 怎么判断算法是否收敛?
- 怎么样保证 $\alpha_i$ 和 $\alpha_j$ 在优化过程中不会打破约束条件的限制?
- 如何对 $\alpha_i$ 和 $\alpha_j$ 进行最优化动作
- 你可能还会有其他的问题 balabalabala…
我们一一来解决,解决了这些问题,SMO 算法也就完成了。
如何验证算法是否收敛?
对于这里的QP问题来说,最优解一定会满足 KKT 条件,在这个问题中,KKT条件如下: $$\begin{split}&\alpha_i = 0 &\rightarrow &y_i(w^{\mathrm{T}}x_i + b) \geq 1\newline &0 \leq \alpha_i \leq C &\rightarrow &y_i(w^{\mathrm{T}}x_i + b) = 1\newline &\alpha_i = C &\rightarrow &y_i(w^{\mathrm{T}}x_i + b) \leq 1 \end{split}$$ 只要所有的 $\alpha_i$ 在一定的 tolerance 内满足了上述KKT条件,我们就可以说算法已经收敛了。
怎么样保证 $\alpha_i$ 和 $\alpha_j$ 在优化过程中不会打破约束条件的限制
我们首先来看一下 $\alpha_i$ 和 $\alpha_j$ 会满足怎么样的约束条件?不失一般性,为了方便表示,接下来用$\alpha_1$ 和 $\alpha_2$ 来替代 $\alpha_i$ 和 $\alpha_j$,根据第二个限制条件,由于我们固定其他的 $\alpha_i$ 不变,我们有
$$\alpha_1 + \alpha_2\underbrace{y_1y_2}_{S}=$$
$$\underbrace{-y_1\sum_{i=3}^m{\alpha_iy_i}}_{\zeta}=$$
$$\alpha_1^{old} + \alpha_2^{old}\underbrace{y_1y_2}_{S}$$
这也就是说,在优化过程中 $\alpha_1$ 和 $\alpha_2$ 必须满足 $\alpha_1 + \alpha_2S = \zeta$ 这条直线的限制,根据 $y_1,y_2$ 是否同号,分别讨论 S 的值,如下图所示:
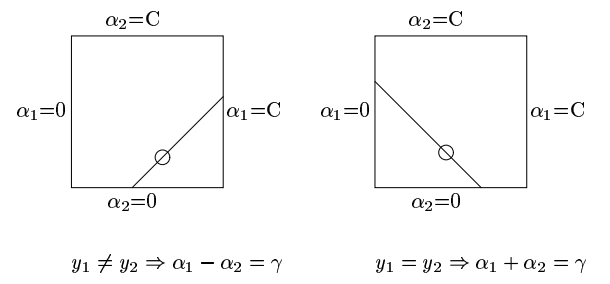 可以看到,最后只要能够确保更新的 $\alpha_1,\alpha_2$ 在图中的直线上,就可以保证约束条件没有被违反。
可以看到,最后只要能够确保更新的 $\alpha_1,\alpha_2$ 在图中的直线上,就可以保证约束条件没有被违反。
怎么对$\alpha_1,\alpha_2$ 做最佳化动作?
首先容易想到的是,用$\alpha_1,\alpha_2$ 之间的等式关系: $\alpha_1 + \alpha_2S = \zeta$ 消去一个变量,不失一般性,这里我们不妨消去 $\alpha_1$,这样目标函数中就只剩 $\alpha_2$ 了,再仔细观察,发现 $\alpha_2$ 的最高项次数是 2,这也就是说 $W(\alpha)$ 可以整理成 $ax^2 + bx + c$这种形式,OK,问题解决了,这种二次函数谁不会求最大值啊,初中数学水平即可,但是,别忘了,$\alpha_2$ 的取值是有范围的,看看上面的那条直线,如果求出来的极值点$\alpha_2$ 正好落在直线范围内还好,如果不再范围内就惨了,求出来的值没法用,还有一种更惨的情况,万一这个二次函数压根就没有最大值(退化成直线甚至开口向上)怎么办,根本就没有最大值,那又该怎么办?其实对于后面这两种情况,你动手画一些示意图就可以看到,对于极大值点不在约束范围内和没有极大值点这两种情况,此时 $W(\alpha)$ 的最大值一定是在 $\alpha_2$ 的左右边界之一取得,如下图所示。 可见这样话,我们只需要在实现的时候针对特殊情况比较一下边界值即可。 下面我们来整理一下上面的听起来很简单的 $ax^2 + bx + c$: 首先有: $$\begin{split}W(\alpha) &= \alpha_1 + \alpha_2 + Constant - \frac12( y_1y_1K(x_1,x_1)\alpha_1^2+ \newline &y_2y_2K(x_2,x_2)\alpha_2^2 + 2y_1y_2K(x_1,x_2)\alpha_1\alpha_2 \newline &+2(\sum_{i=3}^n\alpha_iy_ix_i^\mathrm{T})(\alpha_1y_1x_1+\alpha_2y_2x_2+Constant))\end{split}$$ 为了进一步简化,我们对符号作如下约定: $$K_{11} = K(x_1,x_1),K_{22} = K(x_2,x_2),K_{12} = K(x_1,x_2)$$ $$\begin{split}v_j&=\sum_{i=3}^n\alpha_iy_iK(x_i,x_j)\newline&=x_jw^{old} - \alpha_1^{old}y_1K(x_1,x_j) -\alpha_2^{old}y_2K(x_2,x_j)\newline&=u_j^{old} - b^{old} - \alpha_1^{old}y_1K(x_1,x_j) - \alpha_2^{old}y_2K(x_2,x_j)\end{split}$$ 其中,$u_j^{old} = x_jw^{old} + b^{old}$ 是支持向量机在旧的参数 $w^{old}$下对 $x_j$ 所做的预测。
重新整理一下,并用 $\zeta - \alpha_2S$ 替代 $\alpha_1$现在我们有: $$\begin{split}W(\alpha) &= \alpha_1 + \alpha_2 \newline&- \frac12( K_{11}\alpha_1^2+K_{22}\alpha_2^2 + 2SK_{12}\alpha_1\alpha_2 \newline & 2y_1v_1\alpha_1 + 2y_2v_2\alpha_2) + Constant\newline &=\zeta - \alpha_2S + \alpha_2 - \frac 12 (K_{11}(\zeta - \alpha_2S)^2 \newline & + K_{22}\alpha_2^2 + 2SK_{12}(\zeta - \alpha_2S)\alpha_2 \newline & + 2y_1v_1(\zeta - \alpha_2S) + 2y_2v_2\alpha_2 ) + Constant\newline \end{split} $$
接下来,再推导五六步即可得到如下形式(没什么技巧,直接拆开化简合并就行): $$\begin{split}W(\alpha) &= (-\frac12K_{11} - \frac12K_{22} + K_{12})\alpha_2^2 + \newline&(1 - S + SK_{11}\zeta - SK_{12}\zeta + y_2v_1 -y_2v_2 )\alpha_2 + Constant \newline &= \frac12(2K_{12} - K_{11} - K_{22})\alpha_2^2 \newline&+ (1 - S + SK_{11}\zeta - SK_{12}\zeta + y_2v_1 -y_2v_2 )\alpha_2 + Constant \end{split}$$ 设 $\eta = 2K_{12} - K_{11} - K_{22}$, 同时观察上式中 $ \alpha_2$的系数,分别将 $\zeta$ 和 $v_j$ 的定义代入: $$\begin{split}& 1 - S + SK_{11}\zeta - SK_{12}\zeta + y_2v_1 -y_2v_2 \newline = & 1 - S + SK_{11}(\alpha_1^{old} + \alpha_2^{old}S) - SK_{12}(\alpha_1^{old} + \alpha_2^{old}S) \newline &+ y_2(u_1^{old} - b^{old} - \alpha_1^{old}y_1K(x_1,x_1) - \alpha_2^{old}y_2K(x_2,x_1)) \newline &-y_2(u_2^{old} - b^{old} - \alpha_1^{old}y_1K(x_1,x_2) - \alpha_2^{old}y_2K(x_2,x_2))\newline =& 1- S + (K_{11} + K_{22} - 2K_{12})\alpha_2^{old} + y_2(u_1^{old} - u_2^{old})\newline =& y_2^2 - y_1y_2 + (K_{11} + K_{22} - 2K_{12})\alpha_2^{old} + y_2(u_1^{old} - u_2^{old})\newline =& y_2((u_1^{old} - y_1) - (u_2^{old} - y_2)) - \eta\alpha_2^{old}\newline =&y_2(E_1^{old} - E_2^{old}) - \eta\alpha_2^{old} \end{split}$$ 其中,$E_i = u_i - y_i$
OK,经过了这么多乱七八糟(其实还蛮清晰的)的式子,我们得到了 $W(\alpha)$ 的一个简洁的表示: $$W(\alpha) = \frac 12 \eta \alpha_2^2 + (y_2(E_1^{old} - E_2^{old}) - \eta\alpha_2^{old})$$
干净利索了,我们来求最大值吧,首先求一阶导数和二阶导数。 $$\frac{\mathrm{d}W(\alpha)}{\mathrm{d}\alpha_2} = \eta\alpha_2 + (y_2(E_1^{old} - E_2^{old}) - \eta\alpha_2^{old})\newline \frac{\mathrm{d}^2W(\alpha)}{\mathrm{d}\alpha_2^2} = \eta$$
注意到,$\eta = 2K_{12} - K_{11} - K_{22} \leq 0$, 因为 $$\begin{split} & 2K_{12} - K_{11} - K_{22} \newline =&2\phi(x_1)^{\mathrm{T}}\phi(x_2) - \phi(x_1)^{\mathrm{T}}\phi(x_1) - \phi(x_2)^{\mathrm{T}}\phi(x_2) \newline =&-(\phi(x_2) - \phi(x_1))^2 \newline \end{split} $$
令 $\frac{\mathrm{d}W(\alpha)}{\mathrm{d}\alpha_2} = 0$, 我们有 $$ \alpha_2^{new} = \alpha_2^{old} + \frac{y_2(E_2^{old} - E_1^{old})}{\eta} $$
如果 $\eta < 0$, 那么 $\alpha_2^{new}$ 就是极值点,但是我们还不知道这个极值点是否会满足我们的约束条件,我们需要求出 $\alpha_2$ 的取值范围再来讨论,$\alpha_2$ 的范围如下:
- 当 $y_1,y_2$ 同号即 $ S=1$ 时,根据此时直线的方向,$\alpha_2$ 的取值范围是 $(\max(0,\zeta - C),\min(C,\zeta))$,具体来说,当 $\zeta > C$ 时,$\alpha_2 \in (\zeta -C,C)$;当 $\zeta < C$ 时,$\alpha_2 \in (0,\zeta)$,这些情况如下图所示:
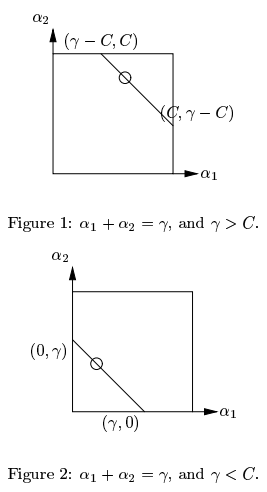
- 当 $y_1,y_2$ 异号即 $ S=-1$ 时,根据此时直线的方向,$\alpha_2$ 的取值范围是 $(\max(0,-\zeta),\min(C,C - \zeta))$,具体来说,当 $\zeta > 0$ 时,$\alpha_2 \in (0,C - \zeta)$;当 $\zeta < 0$ 时,$\alpha_2 \in (-\zeta,C)$,此时情况如下图所示:
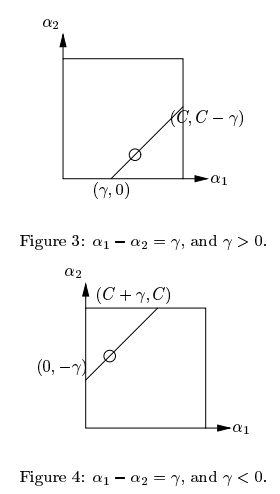
总之,根据对应的条件求出 $\alpha_2$ 的上下界,我们记为 $L,H$后,我们需要将求的无约束下的最优值 $\alpha_2^{new}$ 与 $L,H$ 进行比较以使得最终的解满足约束条件,我们有如下讨论:
- 如果 $\alpha_2^{new} > H$,此时可以验证 对于开口向下的目标二次函数会在 $H$ 处取得最大值。
- 如果 $L <\alpha_2^{new} < H$, 此时满足条件。
- 如果 $\alpha_2^{new} < L$,此时可以验证 对于开口向下的目标二次函数会在 $L$ 处取得最大值。
总的来说,我们需要对 $\alpha_2^{new}$ 作如下的裁剪操作: $$\alpha_2^{new} = \begin{cases}H, when \ \alpha_2^{new} > H\newline \alpha_2^{new}, when \ L<\alpha_2^{new} < H\newline L, when \ \alpha_2^{new} < L \end{cases}$$
以上讨论的这些大多数时候都是成立的,但是也有$\eta = 0$ 的情况存在,比如混入了相同的训练样本,此时,目标函数直接退化成了一条直线,最大值肯定是在区间的断点处取得,我们只需要将 $L,H$分别带入将 $\alpha_2^{new}$ 设为目标函数较大的那个端点即可。
得到 $\alpha_2^{new}$ 后,我们最后根据 $\alpha_1 + \alpha_2S = \zeta$ 来更新 $\alpha_1$, 有 $$\alpha_1^{new} = \alpha_1^{old} - S(\alpha_2^{new} - \alpha_2^{old})$$ 由此,我们完成了对参数 $\alpha$ 的更新。
此外,每一步中,我们都要更新参数 $b$, 其中更新的公式为: $$b_1 = b^{old} - E_1 + y_1(\alpha_1^{old} - \alpha_1^{new})K_{11}+y_2(\alpha_2^{old} - \alpha_2^{new})K_{12} \newline b_2 = b^{old} - E_2 + y_1(\alpha_1^{old} - \alpha_1^{new})K_{12}+y_2(\alpha_2^{old} - \alpha_2^{new})K_{22}$$
上述两个等式是通过KKT条件推出来的,注意此时可以看作仅有 $\alpha_1,\alpha_2$ 两个变量的二次规划问题,对于不在边界上的 $\alpha, \ \ i.e. 0<\alpha<C,$ 根据KKT条件有 $y_i(w^{\mathrm{T}}x_i + b) = 1$,由此可以推出 $b$ 的值, 上述两个等式就是$\alpha_1,\alpha_2$ 分别不在边界上时所求出的对应的 $b$ 值。 那我们应该选哪个来更新 $b$ 呢?
- 如果$\alpha_1,\alpha_2$有且仅有一个不在边界上,就用对应的$b$进行更新。
- 如果$\alpha_1,\alpha_2$都不在边界上,随意一个 $b$ 值都可以进行更新。
- 如果$\alpha_1,\alpha_2$都在边界上,$b_1$ 与 $b_2$ 之间的任意 值都可以进行更新。
第一点非常好理解,第二点是因为在都满足KKT条件的情况下,b值应该是唯一的,关于第三点我一直都有疑问,在这里尝试说一下我的想法, 想法非常地 trivial: 分两种情况讨论
- 因为$\alpha_1,\alpha_2$都在边界上,假设$\alpha_1,\alpha_2$的值相同,这也就是说 $\alpha_1,\alpha_2$ 在刚刚的那一轮更新中一定是同增(对应值为C)或者同减(对应值为0),如若不然,那么在之前的更新中必然已经出现了违反约束的情况,而我们实际上进行了裁剪,所以这种情况不存在,此时同增同减意味着,$y_1,y_2$异号,这样的话,由于上述计算 $b$ 的公式 是从$y_i(w^{\mathrm{T}}x_i + b) = 1$的条件下推出的,此时在边界上需要满足的是不等关系,解对应的两个不等式,由于$y_1,y_2$异号,这样合理的 $b$ 一定在 $b_1,b_2$之间。
- 与1) 类似,$\alpha_1,\alpha_2$ 的值如果不同的话,那么$y_1,y_2$则一定同号,同样的,合理的 $b$ 一定在 $b_1,b_2$之间。
如何选择待更新的$\alpha_1,\alpha_2$
to be continued。。。
SMO的一个简单实现
下面是一个简化版的SMO-SVM实现,有很多方面没有照顾到,后续会再实现一个较为完整的版本,此处仅用作展示算法流程。
#!/usr/bin/env python
# encoding: utf-8
"""
@author: lebronran
@site: https://chosenone75.github.io
@time: 2017/8/29 0029 19:04
"""
from __future__ import print_function
from __future__ import division
import numpy as np
import re
import time
# helper function for the implement of simplified SMO algorithm
def loadDataSet(filename):
examples = []
labels = []
with open(filename,"rb") as f:
for line in f:
nums = re.split("\s+",line.strip())
examples.append([float(nums[0]),float(nums[1])])
labels.append(float(nums[2]))
return np.array(examples),np.array(labels)
def selectJRand(i,m):
j = i
while j == i:
j = int(np.random.uniform(0,m))
return j
def clipAlpha(alpha_new,H,L):
if alpha_new > H:
alpha_new = H
elif alpha_new < L:
alpha_new = L
return alpha_new
def simpleSMO(training_x,training_y,C,toler,maxiter=100):
'''
:param training_x: training set of example
:param training_y: the class labels of training examples
:param C: the factor tradeoff between accuracy and margin
:param toler: a small number for numbericl stablity, typically 0.001
:param maxiter: the number of the iteration
:return: weight, bias
'''
examples = np.matrix(training_x)
labels = np.matrix(training_y).transpose()
b = 0
m,n = np.shape(examples)
alphas = np.matrix(np.zeros(shape=(m,1)))
iter = 0
while iter < maxiter:
numChanged = 0
for i in range(m):
fXi = float(np.multiply(alphas,labels).T * (examples * examples[i,:].T) + b)
Ei = fXi - float(labels[i])
if (labels[i] * Ei < -toler and alphas[i] < C) or (
labels[i] * Ei > toler and alphas[i] > 0):
j = selectJRand(i,m) # so-called the simplified SMO
fXj = float(np.multiply(alphas, labels).T * (examples * examples[j, :].T) + b)
Ej = fXj - float(labels[j])
alpha_i_old = alphas[i].copy()
alpha_j_old = alphas[j].copy()
if labels[i] != labels[j]:
L = max(0,alphas[j] - alphas[i])
H = min(C,C+alphas[j]-alphas[i])
else:
L = max(0,alphas[i] + alphas[j] - C)
H = min(C,alphas[i] + alphas[j])
if L == H: print("L==H");continue
eta = 2.0 * examples[i,:] * examples[j,:].T - \
examples[i, :] * examples[i, :].T - \
examples[j,:] * examples[j,:].T
if eta >= 0: print("eta is greater than zero,just move on here");continue
alphas[j] -= labels[j] * (Ei - Ej) / eta
alphas[j] = clipAlpha(alphas[j],H,L)
if abs(alphas[j] - alpha_j_old) < 0.0001:
print("the step size is not enough, just move on here")
continue
alphas[i] += labels[i] * labels[j] * (alpha_j_old - alphas[j])
b1 = b - Ei - labels[i]*(alphas[i] - alpha_i_old)\
*examples[i, :] * examples[i, :].T \
- labels[j]*(alphas[j] - alpha_j_old) \
*examples[i, :] * examples[j, :].T
b2 = b - Ej - labels[i] * (alphas[i] - alpha_i_old) \
* examples[i, :] * examples[j, :].T \
- labels[j] * (alphas[j] - alpha_j_old) \
* examples[j, :] * examples[j, :].T
# update the bias
if alphas[i] > 0 and alphas[i] < C:
b = b1
elif alphas[j] > 0 and alphas[j] < C:
b = b2
else:
b = (b1 + b2) / 2
numChanged += 1
print("iter : %d, i: %d, %d pairs changed" % (iter,i,numChanged))
if numChanged == 0:
iter += 1
else:
iter = 0
print("iternum: %d." % iter)
return b,alphas
training_x,training_y = loadDataSet("data/testSet.txt")
begin = time.time()
b,alphas = simpleSMO(training_x,training_y,0.6,0.001,40)
end = time.time()
print("The time costed totally : %d s." % (end - begin))
print(b)
print(alphas[alphas>0])
参考资料
还有几个比较好的英文资料,但出处没有找到,请自行google keerthi-svm sequential-minimal-optimization-a-fast-algorithm-for-training-support-vector-machines